Development Guidelines¶
As developers of MPAS, we attempt to make the code look as uniform as we can across the entire code-base. In order to enforce this, there are a set of guidelines developers should follow.
Each core has a name and an abbreviation. For example, the shallow water core is called sw and its abbreviation is sw, but the ocean core is called ocean and its abbreviation is ocn.
All subroutines should be named in a manner which prevents namespace conflicts. Shared functions/subroutines are simply named mpas_subroutine_name. Core specific functions/subroutines are named mpas_abbrev_subroutine_name (where abbrev is replaced with the core’s abbreviation; for e.g., mpas_atm_time_integration).
Subroutine names should all be lower case, with underscores in place of spaces (see the above example).
Variable names should be mixed-case (e.g. cellsOnCell rather than cells on cell).
In general, variable names should be self-descriptive (e.g. nCells rather than n).
Subroutines and modules should be appropriately documented. Shared portions of MPAS code use Doxygen comments, but core developers are free to decide what method of documenting they prefer.
Development of shared parts of MPAS needs reviews from multiple core maintainers prior to a merge.
Development within a core should be approved by other core developers before being merged into that core.
Development within a core should follow the practices of that core’s developer group for documentation, etc.
Core-related testing is the responsibility of that core’s maintainers/developers.
Core maintainers must approve changes before the changes appear on the shared repository. Core maintainers are also responsible for reviewing changes to shared code that affects multiple cores.
General Code Introduction¶
The MPAS framework makes extensive use of derived data types - many of which are defined in src/framework/mpas_grid_types.F, but some of the data types are not defined until build time. Registry is used to define both fields and structures. A field is the lowest level of data within the MPAS framework, and contains a description of the field along with the actual field data. Allowed field types are defined in the previously mentioned file, and Registry makes use of these type definitions.
A structure is a larger grouping of fields and dimensions. Structures can have multiple time levels, or a single time level. A structure can be used to group fields and define a part of the model, e.g. the mesh definition.
Structures are grouped into blocks. A block contains all relevant information for a particular part of your domain. The entire domain is subdivided horizontally into blocks. Within the model, blocks are stored in a linked list.
The largest structure is the domain, which defines all blocks that are part of a particular MPI process’s computational domain.
The following diagram is provided as a visual aid for the layout of data within the MPAS framework. It is not exhaustive, so please refer to any core-specific references to get a more complete list of how derived data types are laid out in the specific core.
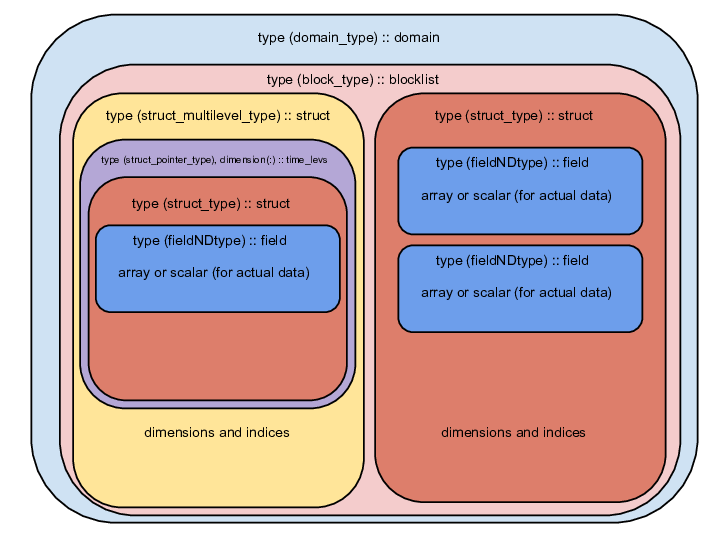
Visual diagram of MPAS derived data type layout¶
In the actual MPAS code, the above diagram converts to the following lines.
domain % blocklist % struct1 % field1 % array
domain % blocklist % struct1 % field2 % scalar
domain % blocklist % struct2 % time levs (1) % struct2 % field1 % array
domain % blocklist % struct2 % time levs (1) % struct2 % field2 % scalar
As the blocklist structure is a linked list of blocks, one can iterate over the list of blocks in the following manner.
type (block_type), pointer :: block_ptr
block_ptr => domain & blocklist
do (while(assiciated(block_ptr))
... do stuff on block ...
block_ptr => block_ptr % nest
end do
In order to create new fields or structures, a developer needs to modify Registry.xml for the particular core. The definition of Registry.xml is stored in src/registry/Registry.xsd. This schema file can also be used to validate a Registry.xml file using any XML validator.
Parallelization Strategy¶
Currently within MPAS, the only parallelization strategy is MPI. This section is intended to be a basic introduction to the use of MPI within MPAS.
Within MPAS, the horizontal dimensions are partitioned into blocks. A block is essentially a self-describing portion of the global domain. In the event MPAS is run with a single processor, only one block is used, which encompasses the entire domain. These partitions are generated by using an external tool, METIS, that partitions a graph file.
Upon initialization of MPAS, the graph partition file is read in. Each processor is then responsible for constructing its blocks. A processor can be in charge of one or multiple blocks - meaning it is responsible for determining the correct answer. On a single MPI task, all blocks are stored in a linked list as described in General Code Introduction. Within the block are lists of fields - each of which has some number of halos. A halo is a boundary of ghost elements that ensure the correct answer on actual owned elements. The two figures below show how halo layers may be defined in a simulation with two cell halo layers. Edge and Vertex halo layers share a definition.
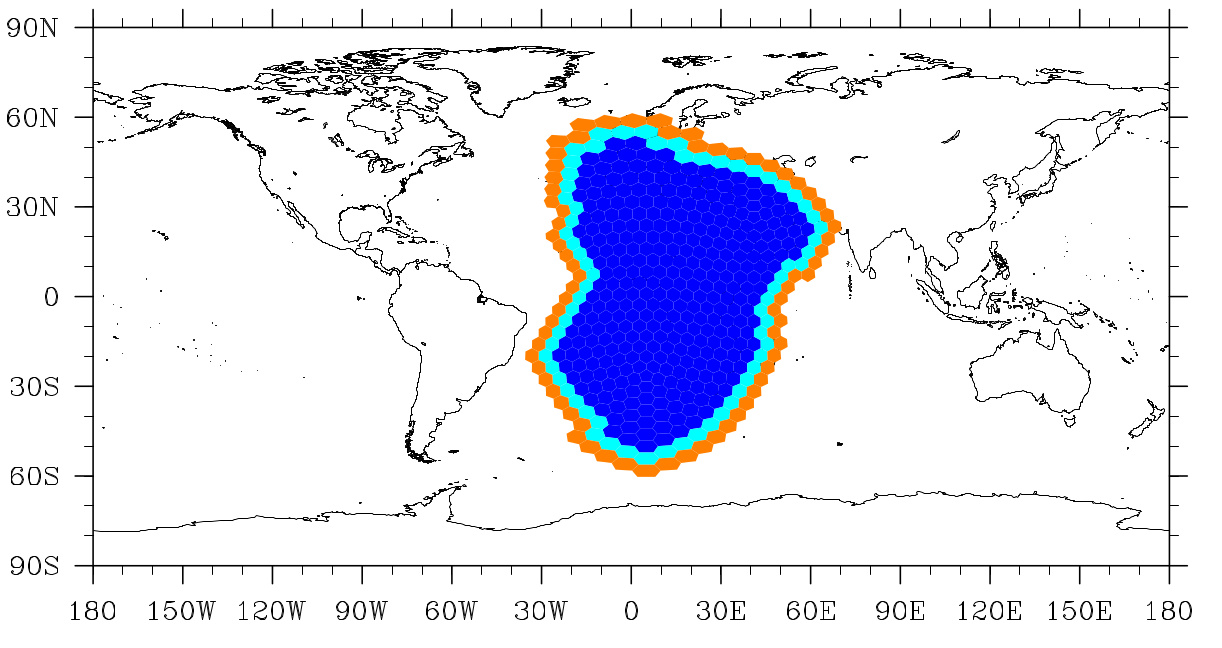
The block’s owned cells are shown in dark blue; the first halo layer cells are shown in light blue, and the second halo layer cells are shown in orange.¶
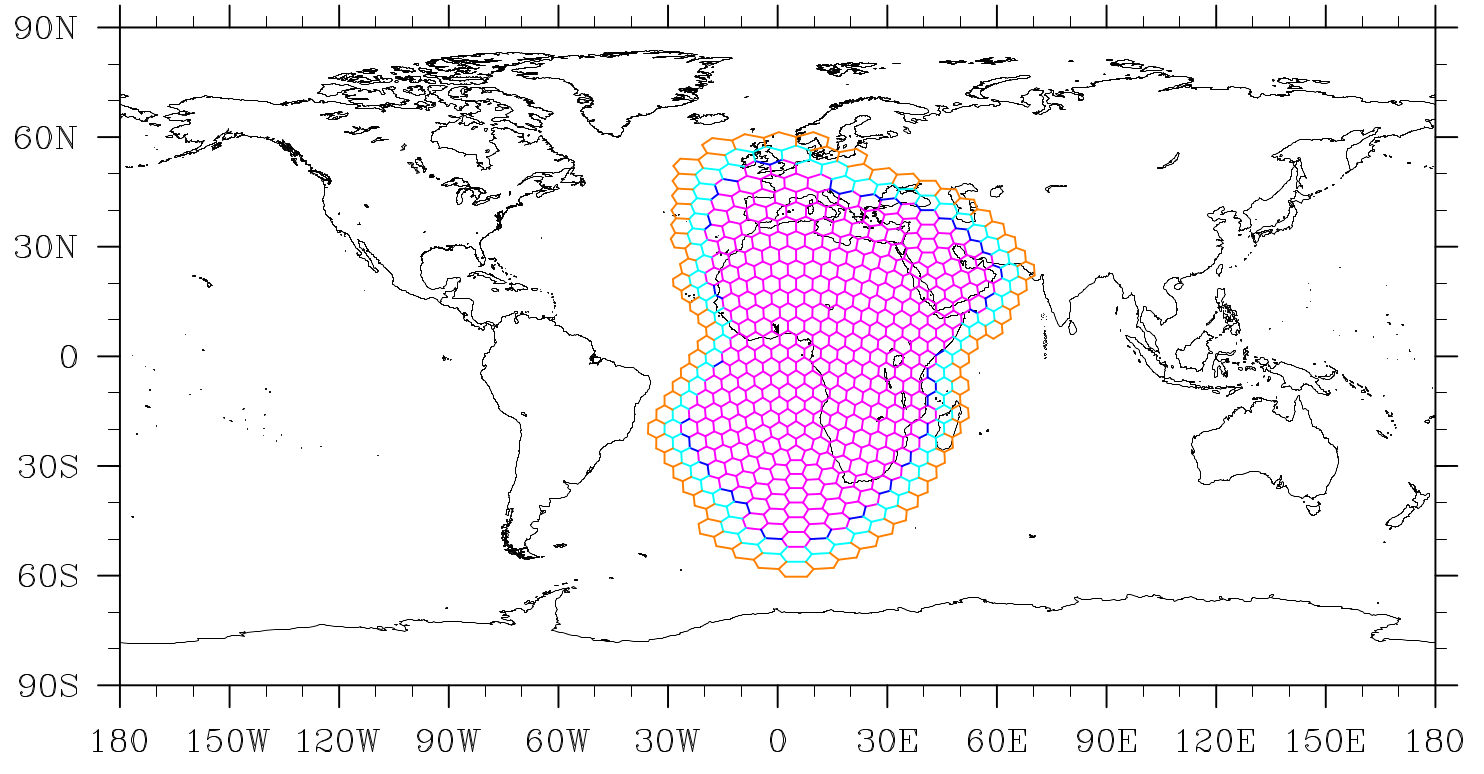
The block’s owned edges are represented with pink edges; the dark blue edges on the pink perimeter represent the first halo layer edges; light blue represents the second halo layer edges; orange represents the third halo layer edges.¶
Cells make up the primary mesh within MPAS. Cell halos are described below.
0-Halo: All “owned” cells
1-Halo: All cells that border 0-Halo cells, but are not O-Halo cells
2-Halo: All cells that border 1-Halo cells, but do not belong to a lesser-valued halo
3-Halo: All cells that border 2-Halo cells, but do not belong to a lesser-valued halo
Cells can have an arbitrary number of halos, in which case this incremental definition continues until the last halo layer.
Edges and Vertices have a slightly different definition and always include an additional layer.
0-Halo: All “owned” edges/vertices
1-Halo: All edges/vertices that border 0-Halo cells that are not 0-Halo edges/vertices
2-Halo: All edges/vertices that border 1-Halo cells that are not 1-Halo edges/vertices
3-Halo: All edges/vertices that border 2-halo cells that are not 2-Halo edges/vertices
…
As with cells, edges/vertices with a value greater than 1-halo use the same definition until the last halo layer.
MPI communication occurs between these halo layers. One block needs to send some of its 0-halo elements to other blocks, and it needs to receive other block’s 0-halo elements to put into its halo layers. This communication occurs through exchange lists, which are built during initialization. An exchange list describes MPI sends, MPI receives, and local copies.
A local copy occurs when two blocks need to communicate and are owned by the same MPI task. In this case, the exchange list describes where data can be found in the owning blocks list, and where it should go in the receiving blocks list.
An MPI send exchange list describes with which processor the communication needs to occur. It also describes which elements need to be read from the owning blocks list, and where those elements should be placed in the sending buffer.
An MPI receive exchange list describes with which processor the communication needs to occur. It also describes how to unpack data from the buffer into the halo layers.
Halo exchange routines are provided in src/framework/mpas_dmpar.F. These halo exchange routines internally loop over all blocks in the list of blocks, starting from the block that was passed in. Because of this, developers should always pass in the first block’s field (i.e. domain % blocklist % struct % field) to these routines, and should never put a halo exchange within a block loop. A halo exchange within a block loop will only work properly if there is only a single block per processor.
A generic interface for halo exchanges of all fields is provided as follows:
mpas dmpar exch halo field(field , haloLayersIn)
The argument haloLayersIn is optional, and allows specification of which halo layers should be communicated. This allows the developer more control over the message size.
Currently there is no standard way of implementing OpenMP in MPAS. None of the shared code has any OpenMP directives in it, but developers are investigating the best method of implementing OpenMP in MPAS.