Infrastructure Development for Regional Coupled Modeling Environments¶
Final Report
September 30, 2003
Authors
John Michalakes, Senior Software Engineer, NSF National Center for Atmospheric Research
Matthew Bettencourt, Center for Higher Learning/ U. Southern Miss.
Daniel Schaffer, Forecast Systems Laboratory/CIRA
Joseph Klemp, National Center for Atmospheric Research
Robert Jacob, Argonne National Laboratory
Jerry Wegiel, Air Force Weather Agency
Abstract¶
Understanding and prediction of geophysical systems have moved beyond the capabilities of single-model simulation systems coupling into the area of multi-model multi-scale interdisciplinary systems of interacting coupled models. Terascale computing systems and high-speed grid-enabled networks enable high-resolution multi-model simulation at regional and smaller scales. Exploiting such capabilities is contingent, however, on the ability of users to easily and effectively employ this power in research and prediction of hurricane intensification, ecosystem and environmental modeling, simulation of air quality and chemical dispersion, and other problems of vital concern. This project, funded under the DoD High Performance Modernization PET program, has developed and demonstrated flexible, reusable software infrastructure for high-resolution regional coupled modeling systems that abstracts the details and mechanics of inter-model coupling behind an application program interface (API).
As discussed in our original proposal, effective software infrastructure for high-performance simulation addresses three levels of the problem: managing shared- and distributed-memory parallelism within individual component models (L1), efficiently translating and transferring forcing data between coupled component grids each running in parallel (L2), and presenting the simulation system as a problem solving environment (L3). Intra-model (L1) software infrastructure is provided by the Advanced Software Framework (ASF) already developed for the Weather Research and Forecast (WRF) model. Under this project we have developed L2 infrastructure: a detailed specification for an I/O and Coupling API and two reference implementations of the API. Using these reference implementations, we have assembled, run, and benchmarked proof-of-concept coupled climate-weather-ocean (CWO) applications. The results demonstrate that the regional coupling infrastructure developed under this project (1) is flexible and interoperable over the range of target component applications, API implementations, and computing platforms, including computational grids, (2) is efficient, introducing little additional run-time overhead from the coupling mechanism itself, and (3) can therefore provide significant benefits to the DoD CWO research community.
Introduction¶
The requirements for understanding and prediction of geophysical systems has moved beyond the capabilities of single-model simulation systems coupling into the area of multi-model multi-scale interdisciplinary systems of interacting coupled models:
In the realm of geophysical modeling the current state-of-the-art models have the capability to run at very high spatial resolutions. This capability has led to a drastic increase in the accuracy of the physics being predicted. Due to this increased numerical accuracy, once neglected effects, such as non-linear feedback between different physical processes, can no longer be ignored. The ocean’s deep water circulation, surface gravity waves, and the atmosphere above can no longer be treated as independent entities and must be considered a single coupled system (see Bettencourt et al., 2002).
Terascale computing systems and high-speed grid-enabled networks are enabling high-resolution multi-model simulation at regional and smaller scales. Exploiting such capabilities is contingent, however, on the ability of users to easily and effectively employ this power in research and prediction of hurricane intensification, ecosystem and environmental modeling, simulation of air quality and chemical dispersion, and other problems of vital concern.
This project, funded under the DoD High Performance Modernization PET program, has developed and demonstrated flexible, reusable software infrastructure for high-resolution regional coupled modeling systems that abstracts the details and mechanics of inter-model coupling behind an application program interface (API) that also serves as the API to I/O and data format functionality. The application need not know or care about the entity on the other side, whether a self-describing dataset on a disk or another coupled application. Moreover, knowledge of the underlying mechanisms for parallel transfer, remapping, masking, aggregation, and caching of inter-model coupling data are implemented behind the API and not within the application code itself. Thus, computer/network-specific or application-specific library implementation of the API may be substituted at link-time without modifying the application source code; developers of API implementations may be assured that their coupling software will be usable by any application that calls the API. Lastly, component models are better positioned to make use of other packages and frameworks for model coupling, such as the NOAA/GFDL Flexible Modeling System (FMS) and, when it becomes available, the NASA Earth System Modeling Framework (ESMF).
Under this project we have developed a detailed specification for an I/O and Coupling API. This specification is provided as Appendix A. We have also developed two reference implementations of the API using the Model Coupling Toolkit (MCT), a coupling library that supports tightly-coupled a priori scheduled interactions between components that was developed for the Community Climate System Model (CCSM) project, and the Model Coupling Environment Library (MCEL) to support loosely coupled peer-to-peer data-driven interactions between components within coupled ecosystem models that was developed as part of the High Fidelity Simulation of Littoral Environments (HFSoLE) project. The MCT implementation of the I/O and Coupling API is described in Appendix B; the MCEL implementation in Appendix C. Finally, we have assembled, run, and benchmarked proof-of-concept coupled applications using the MCT and MCEL implementations. These are described in the sections that follow. In the next section, an overview of model coupling is provided. In Section 4, we describe an atmosphere/ocean coupled system use of the MCT implementation of the I/O and Coupling API to exchange surface fields between the WRF model and the Rutgers Ocean Modeling System (ROMS). Section 5 describes an atmosphere/coastal ocean/wave model coupling using the MCEL implementation of the I/O and Coupling API to exchange surface fields between WRF, NCOM, and SWAN components.
Model Coupling¶
There are two modes for coupling between models of different geophysical processes: subroutinization and componentization. In a subroutinized coupling, the coupled model – e.g. a physical parameterization such as a microphysics scheme, a land surface model, or an chemistry model – appears as an integral part of the model, such as a model of atmospheric dynamics. Synchronization and communication is through calls and argument lists to the components from the driver model. Computationally, subroutinized coupling is often the most efficient mode of coupling because the cost is that of a subroutine call, but it requires that one model be in control, it severely limits opportunities for concurrency between components, and it requires that components be highly code compatible so that components developed independently by other groups may be difficult to integrate without significant recoding that breaks the code heritage from the originally developed code.
Componentized coupling, which the infrastructure developed under this project addresses, maintains the component codes in close to their original forms providing considerably more flexibility and opportunities for ad hoc switching between different coupled components, at the potential cost of some execution efficiency. However, atmospheric, ocean, and other component models typically exchange a relatively small amount of data (two-dimensional fields at their boundaries) at coupling intervals that are relatively long in terms of the amount of simulation that components perform between. Componentized coupling presents opportunities for concurrent execution of components. Finally, since the mechanics of coupling can be placed outside the components, considerable optimization can occur behind the I/O and Coupling API without disturbing the component codes themselves.
Concurrently coupled components execute concurrently on separate sets of processors, sending and receiving coupling data between the processor sets (right side of Figure XX). Components with different execution speeds can be paces by assigning varying numbers of processors to each component, addressing load imbalance. Non-parallel or modestly-parallel components are able to interact with fully parallelized components. Two-way coupled components - that is, pairs of components that both provide data to and depend on data from their peer - can not execute at the same time over the same interval of the simulation. A phase shift must be introduced (for example, an ocean model would run one coupling interval behind an atmospheric mode; generally acceptable in climate simulations) or they must be serialized.
WRF/NCOM/SWAN Coupling through MCEL Implementation of API¶
Loosely coupled peer-to-peer coupled modeling systems of interacting components, referred to as L2-B style coupling in our original proposal, involves supporting ad-hoc (not a priori scheduled), data-driven interactions between a relatively large number of components that produce data for their peers, sending it over the network when they have it, and consume data from other components when it is available. The Model Coupling Environment Library was developed to support such interactions using a client-server process model. The I/O and Model Coupling API developed under this project has been implemented as a common interface to MCEL and has been used to implement a subset of applications from the High Fidelity Simulation of Littoral Environments (HFSoLE) CHSSI project, involving effective, relocatable, high-resolution, dynamically linked mesoscale, meteorological, coastal oceanographic, surface water/groundwater, riverine/estuarine and sediment transport models (see Allard, 2002). The MCEL-based I/O and Model Coupling API is also applicable to a range of multi-scale multi-model simulations that involve component interactions of this type such as air-quality modeling and other ecosystem simulations. This section provides an overview of the MCEL system, a description of the MCEL implementation of the I/O and Model Coupling API developed under this project, and results of proof-of-concept simulations using the API to couple the WRF model with a subset of components in the HFSoLE system.
MCEL overview¶
The Model Coupling Environmental Library (MCEL) was developed to simplify the coupling process for models that exchange data at most every time step. Traditionally, model coupling is performed in one of the three following ways: file Input/Output (I/O), subroutinazation, and a Message Passing Interface (MPI). It was felt that these mechanisms yielded a solution which was too costly or cumbersum to be a longterm viable solution.
The MCEL infrastructure consists of three core pieces: a centralized server, filters, and numerical models. Utilizing a data flow approach, coupling information is stored in a single server or multiple centralized servers. Upon request this data flows through processing routines, called filters, to the numerical models which represent the clients. These filters represent a level of abstraction for the physical or numerical processes that join together different numerical models. The extraction of the processes unique to model coupling into independent filters allows for code reuse for many different models. The communication between these objects is handled by the Common Object Request Broker Architecture (CORBA). In this paradigm the flow of information is fully controlled by the clients.
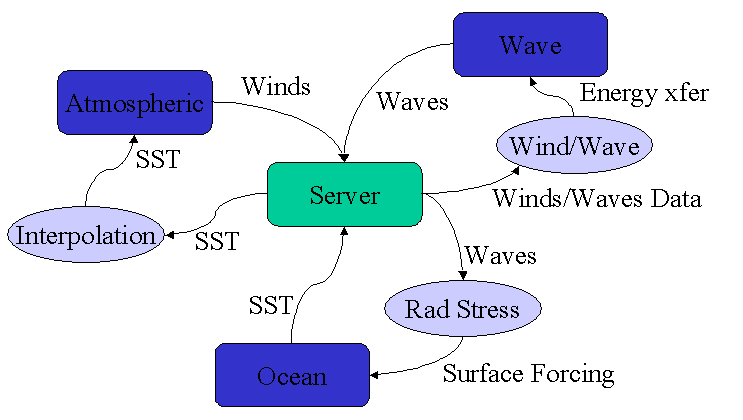
The above figure represents a hypothetical example of a three model MCEL system. It shows three numerical models: Ocean circulation model, atmospheric model and surface gravity wave model. Each model provides information to the centralized server: sea surface temperature (SST), wave height and direction and wind velocities at ten meters above the surface. The SST is used by the atmospheric model; however, it must first be interpolated onto the atmospheric model’s grid. Therefore, the data passes through an interpolation filter prior to delivery. The wave information is transformed into stresses by the RadStress filter using the algorithm by Longuet-Higgins and Stewart (see Longuet-Higgins and Stewart, 1964 <https://doi.org/10.1016/0011-7471(64)90001-4>). The final transformation uses the algorithm by Sajjadi and Bettencourt (see Bettencourt, 2002), which calculates energy transfer from wind and wave information. The filters represent application-independent processes and can be used to process inputs for any wave or circulation application. With the proper combination of filters and models arbitrarily complex modeling suites can be developed.
MCEL implementation of I/O and Coupling API¶
The MCEL implementation of the I/O and Coupling API allows applications to open connections to the MCEL server and filter processes for the purpose of exchanging forcing data between applications as if they were performing I/O. The MCEL implementation allows for components to operate on different extents of the simulated physical domains, using different grids and coordinate systems, and with masking for, for example, land-ocean boundaries. The coupling mode supported by the MCEL implementation is concurrent that is, components run concurrently as separate sets of processes. The communication connections between processes are UNIX IPC sockets within the underlying CORBA system that implements MCEL, and there is a single, non-parallel, connection for each connection. Components running in parallel over multiple processes are expected to collect/distribute decomposed coupling data onto a single process when calling the MCEL implementation of the I/O and Model Coupling API.
The computational domains of a component in a coupled simulation may have different extents. For example, an atmospheric model may simulate over a region that is significantly larger than the domain of a coupled coastal ocean model (see Figure XX) within a coupled ecosystem model for a littoral area; or a limited area atmospheric domain covering a tropical storm may be smaller than the domain of a whole-ocean model. Furthermore, the coordinate systems of the coupled components are likely to be different: a limited-area atmospheric model such as WRF may represent its domain on an equal area Cartesian grid while the underlying ocean is represented on a latitude-longitude coordinate system. Finally, the coupling must account for the fact that an ocean model will only provide data back to the atmosphere over the water, and land areas must be masked. The I/O and Model Coupling API includes semantics for a component to providing necessary georegistration and masking information to the MCEL library.
In the MCEL implementation, a component provides this information when a connection is opened through the API. As described in the API specification, the open-for-write of a connection occurs in two phases: an open for write begin and an open for write commit. Between the calls to the begin and commit, the application performs the sequence of writes for all the fields that constitute one frame of output data from the model. This is the training phase and it allows the API implementation to gather information from the application about the data that will be written. For the MCEL implementation, this is used to capture the information that is then used to georegister and, when necessary, mask the data that will be exchanged with other components. This information is provided to the API as a string of comma separated variable-value pairs in the SysDepInfo argument to the OPEN_FOR_WRITE_BEGIN subroutine; for example, the WRF model calls OPEN_FOR_WRITE_BEGIN and passes it the string:
LAT_R=XLAT,LON_R=XLONG,LANDMASK_I=LU_MASK
which informs the interface it should expect writes of arrays of type real named XLAT and XLONG that contain that latitude and longitude of each grid point in the WRF domain, and an array of type integer that contains either a one or a zero indicating whether a point is over land or not. In the training series of writes that follow the OPEN_FOR_WRITE_BEGIN, the interface will capture and store these arrays for use later, after the OPEN_FOR_WRITE_COMMIT after actual writes to the coupling interface commence.
Reading the MCEL implementation of the API is different in one important respect from a normal I/O read. For reading from the coupling interface, the MCEL implementation of the API will automatically interpolate data provided by another application into the region of the reading-components domain that corresponds to the coupled component. For example, in the case where the WRF model expects to receive sea-surface temperatures from a coastal ocean model on a smaller domain, the MCEL implementation will interpolate the ocean model-provided sst data onto the WRF sst field where they overlap and then smooth (using extrapolation) the data out over a specified radius of influence onto the rest of the WRF sst field. WRF sst data that is outside this radius is unaffected. Thus, the read operation under the MCEL implementation of the I/O and Model Coupling API is more refined than the behavior of a typical I/O read, before which an application might provide a buffer containing uninitialized data, which is entirely overwritten after completion of the read. The MCEL implementation requires that the buffer contain valid field data prior to the read, and this data is then updated with interpolated data from the coupled application. This also means that for components that are running on multiple processes and collecting/distributing the decomposed coupling data on a single process for calling the API, the decomposed field to be read must be collected on one process prior to calling the API, as well as distributing it afterwards. A future implementation of the MCEL implementation of the API will subsume this collection and distribution into the API itself.
Only those subroutines of the I/O and Model Coupling API that are needed for coupling through MCEL are implemented: OPEN_FOR_READ, OPEN_FOR_WRITE_BEGIN, OPEN_FOR_WRITE_COMMIT, READ_FIELD, and WRITE_FIELD. Others are treated as null operations. This allows an application to switch seamlessly between an implementation of the API that targets I/O to a dataset and the coupling implementation that uses MCEL. The other calls that pertain to I/O to a dataset for example, getting and putting meta-data for a self-describing model output file are simply ignored by the MCEL implementation.
In other respects, the behavior and calling semantics of the MCEL implementation of the API are standard with respect to the API specification.
Coupling results¶
This section describes the results of coupling the WRF model with two components of the HFSoLE simulation, the Navy Coastal Ocean Model (NCOM) and SWAN, a wave model, for a coupled domain in the Gulf of Mexico off of the Louisiana and Mississippi shorelines. Figure XX shows the atmospheric domain with the area of the coupling to NCOM and SWAN indicated by the box. The 24-hour simulation period was November 7-8, 2002. The WRF model provided ten meter winds to the MCEL server at hourly intervals. MCEL filters this data and produces wind stresses that are read by NCOM. NCOM, in turn, produces sea surface temperatures that are provided to WRF with a read through the API from an MCEL filter that interpolates the NCOM surface temperatures back onto the WRF skin-temperature field. The results from WRF and NCOM at the end of the 24-hour simulation are shown in Figure XX. Running WRF on 16 processes, NCOM on one process, the MCEL server on one process, and a filter process on one process of on an IBM Power3 SP system (blackforest.ucar.edu), the total run time for the simulation was 1713 seconds, of which approximately 7 seconds were used for inter-model coupling through the API. Thus, the overhead associated with the coupling through the MCEL implementation of the API is negligible.
WRF/ROMS Coupling through (MCT) Implementation of API¶
A second reference implementation of the WRF I/O and Model Coupling API was developed using the MCT to support regular, scheduled exchanges of boundary conditions for tightly to moderately coupled interactions (L2-A style coupling in our original proposal). This was used to couple versions of the WRF and Regional Ocean Modeling System (ROMS). WRF wind stress and heat fluxes were sent to the ocean model and sea-surface temperature were received from ROMS. Three performance benchmarks of the WRF/ROMS coupling were conducted. In addition, the L2-A coupled WRF/ROMS system is being used in follow-on scientific studies involving an idealized hurricane vortex described in.
Concurrent Coupling on a Single Machine¶
WRF was run for a 150x150x20 domain with a time step of 40 seconds; ROMS on a 482x482x15 domain with a time step of 240 seconds. WRF ran for 24 time steps and ROMS for four time steps on an Intel Linux cluster. The models exchanged boundary conditions every ocean time step. Table 1 shows the total run times of the main loop for each model and the times to send and receive data through the I/O and Model Coupling API. Time spent in the MCT implementation was less than 1% of the total run-time for each model. These results are worst-case, since such coupling is usually over intervals that are greater than every ocean time step.
Table 1. Computational and concurrent coupling costs on a single parallel computer
2 |
107.5 |
0.73 |
0.09 |
158.5 |
0.63 |
0.12 |
4 |
61.0 |
0.32 |
0.02 |
57.7 |
0.22 |
0.07 |
8 |
32.9 |
0.18 |
0.01 |
29.5 |
0.11 |
0.05 |
16 |
19.9 |
0.13 |
0.01 |
13.4 |
0.05 |
0.07 |
Concurrent Coupling using Two Machines over a Computational Grid¶
WRF and ROMS were coupled over a rudimentary computational grid. ROMS ran on one Intel Linux node located at the NOAA Pacific Marine Environmental Laboratory (PMEL) in Seattle, Washington; WRF on four Linux nodes located at the NOAA Forecast Systems Laboratory (FSL) in Boulder, Colorado. The Globus Toolkit provided the grid middleware. Table 2 indicates that communication times were less than 2%.
Table 2. Computational and concurrent coupling costs over the Grid
248.0 |
4.74 |
0.04 |
171.0 |
2.69 |
1.49 |
Sequential Coupling on a Single Machine¶
WRF and ROMS were coupled sequentially on four Linux nodes at FSL. Again, as indicated in Table 3, the costs of the MCT implementation communication and interpolation were small.
Table 3. Computational and coupling costs for sequentially coupled WRF/ROMS
4 |
82.0 |
0.10 |
0.02 |
59.8 |
0.27 |
0.11 |
8 |
47.8 |
0.10 |
0.05 |
33.1 |
0.16 |
0.09 |
WRF/ROMS Simulation of Idealized Hurricane¶
This coupling scenario is part of a project studying the physics of hurricane development by investigators at the University of Miami, the University of Washington, and the Model Environment for Atmospheric Discovery (MEAD) project, National Science Foundation (NSF)-funded project at the National Center for Supercomputing Alliance (NCSA). The WRF atmospheric domain was 161 by 161 horizontal points and 30 levels spanning a 1288 km grid initialized to a “background” sounding representing the mean hurricane season in the Caribbean. The ocean domain is 200 by 200 horizontal points by 15 in the vertical, and initialized with temperature stratification typical of the tropical Atlantic. WRF provided wind stress to the ROMS, and the resulting ROMS sea-surface temperature was fed back to WRF. WRF and ROMS were time-stepped at one-minute, and five-minutes respectively, and coupled every 10 minutes. Output was at 30-minute intervals. The load balancing for this concurrent run required eight processors modeling the atmosphere for every oceanic processor.
Figure 2a shows divergent wind-driven surface currents providing an upwelling of cold water centered at the vortex core, with marked asymmetrical structure. This anisotropy affects the convective perturbations in the atmosphere that drive the vortex generation. Figure 2b shows the temperature stratification in the ocean, as well as the vertical velocity field.
Figures 2a, b: Output from WRF/ROMS coupled simulation of simulated hurricane vortex using MCT implementation of I/O and Model Coupling API, courtesy of Chris Moore, NOAA Pacific Marine Environment Laboratory.
Acknowledgements¶
This publication made possible through support provided by DoD High Performance Computing Modernization Program (HPCMP) Programming Environment and Training (PET) activities through Mississippi State University under the terms of Contract No. N62306-01-D-7110.
The original WRF I/O API specification was produced by John Michalakes (NCAR), Leslie Hart, Jacques Middlecoff, and Dan Schaffer (NOAA/FSL) in the Weather Research and Forecast Model development, working group 2: Software Architecture, Standards, and Implementation. We also acknowledge the contributions of Chris Moore (NOAA/PMEL) for technical assistance with the WRF/ROMS coupling, The idea of using an I/O API for model coupling was demonstrated successfully in the early-to-mid 1990s by Carlie Coats and others at the University of Northern Carolina in the U.S. EPA Models-3 I/O API.
APPENDIX A: WRF I/O and Model Coupling API Specification¶
The WRF I/O and Model Coupling Application Program Interface (WRF I/O API, for short) presents a package-independent interface to routines for moving data between a running application and some external producer or consumer of the applications data: for example, a file system or another running program. The WRF I/O API is part of the WRF Software Architecture described in the WRF Software Design and Implementation document. A schematic of the I/O and coupling architecture is shown in the following diagram. The I/O API sits between the application and the package-specific implementation of the I/O or coupling mechanisms and provides a common package-neutral interface to services for model data and metadata input and output. The use of a package-neutral interface allows the WRF applications to be easily adaptable to a variety of implementation libraries for I/O, coupling, and data formatting.
For normal model I/O, the API routines may be implemented using any of a number of packages in use by the atmospheric modeling community. Such packages include GRIB, NetCDF, and HDF. For model coupling the API may be implemented using packages such as the Model Coupling Toolkit (MCT), the Model Coupling Environment Library (MCEL), the Earth System Modeling Framework (ESMF), and others that provide input from and output to other actively running applications. Packages implementing parallel I/O such as MPI-I/O or vendor specific implementations of parallel scalable I/O are also implemented beneath the I/O API . In all cases, this is transparent to the application calling the WRF I/O API. This document provides a specification for the WRF I/O API and is intended for both application programmers who intend to use the API and implementers who wish to adapt an I/O or model coupling package to be callable through the API.
Specification Overview¶
Implementations of the WRF I/O API are provided as libraries in the external directory of the WRF distribution and are documented separately. Names of WRF I/O API routines include a package-specific prefix of the form ext_pkg. This allows for multiple I/O API packages to be linked into the application and selected at run-time and individually for each of the I/O data streams.
I/O API subroutines¶
The calling and functional specification of the WRF I/O API routines are listed in the subsections that follow. In brief, the key routines are:
ext_pkg_ioinit
ext_pkg_open_for_read
ext_pkg_open_for_read_begin
ext_pkg_open_for_read_commit
ext_pkg_read_field
ext_pkg_open_for_write
ext_pkg_open_for_write_begin
ext_pkg_open_for_write_commit
ext_pkg_write_field
ext_pkg_inquiry
In addition, the WRF I/O API provides routines for getting and putting metadata. These routine names have the form
ext_pkg_[get|put]_[dom|var]_[ti|td]_type
where type is one of real, double, integer, logical, or char.
Optional begin/commit semantics for open¶
The WRF I/O API provides for both simple opens for reading and writing datasets or two-stage begin/commit opens, which enables performance improvement for certain implementations of the I/O API. For example, some self-describing formats such as NetCDF are able to write more efficiently if contents of the dataset are defined up-front. The phase of program execution between the call to an open_begin and an open_commit allows for training writes or reads of the dataset that, otherwise, have no effect on the dataset itself. For interface implementations that do not take advantage of a training period, read and write field calls that occur prior to the open commit call will simply do nothing. An interface may also implement simple open_for_read or open_for_write interfaces. Implementations that require (as opposed to simply allowing) begin/commit will return an error status if the simple form is called. Applications can determine the behavior of an implementation using ext_pkg_inquiry.
As mentioned above, the WRF I/O API may employ a begin/commit technique for training the interface of the contents of an output frame. It is important to note, however, that the writing of metadata through the WRF I/O API is not included in this training period. Metadata is only written after the training is concluded and the open operation committed. In addition, and primarily for output efficiency, the metadata should only be written to a dataset once.
Random access¶
By default, an implementation of the WRF I/O API provides random access to a dataset based on the name and timestamp pair specified in the argument list. If an implementation does not provide random access this must be indicated through the ext_pkg_inquiry routine and in the documentation included with the implementation.
For random access, routines that perform input or output on time-varying data or metadata accept two string arguments: the name of the variable/array and a character string index. The variable name provides the name of the variable being read/written; the character string is the index into the series of values of the variable/array in the dataset. The WRF I/O API attaches no significance to the value of an index string, nor does it assume any relationship other than equality or inequality between two strings (that is, no sorting order is assumed); such relationships are entirely the responsibility of the application. The WRF model and other WRF applications treat the index string as a 23 character date string of the form 0000-01-01_00:00:00.0000 that is used as a temporal index.
The API subroutines that deal with order in a dataset (ext_pkg_get_next_time, ext_pkg_set_time, ext_pkg_get_next_var) have no meaning or effect in the case of an API implementation that supports only random access. Typically, model coupling implementations of the WRF I/O API rely on ordered (first in first out) production and consumption of data and do not support random access; however, this is not precluded (MCEL, for example, stores the data on the central server with time stamp information allowing random access for applications that require it).
Sequential access¶
A particular implementation of the WRF I/O API implementation may allow or require sequential access through a dataset or model coupling; however, this behavior must be specified in the package documentation, and the package must return this information through the ext_pkg_inquiry routine.
When a package allows sequential access, the package supports random access of the data but it also remembers the order in which sets of fields having the same date string were written (though not necessarily the order of the fields within each set) and allows the dataset to be read-accessed in that order. Under this form of sequential access, an application program can traverse the dataset by sequencing through time-frames, the set of all fields in the dataset having the same date-string. For example:
1. call ext_pkg_get_next_time(handle, DateStr, Status_next_time)
2. DO WHILE ( Status_next_time .eq. 0 )
3. call ext_pkg_get_next_var (dh1, VarName, Status_next_var)
4. DO WHILE ( Status_next_var .eq. 0 )
5. <Operations on successive fields>
6. call ext_pkg_get_next_var (dh1, VarName, Status_next_var)
7. END DO
8. call ext_pkg_get_next_time(handle, DateStr, Status_next_time)
9. END DO
The call to ext_pkg_get_next_time in line 1 will return the value of the string DateStr for the next set of fields in the dataset. The section of the example code from lines 3 and 7 apply to those fields having the same DateStr. Within this section, the code calls ext_pkg_get_next_var to get the first of those fields, and then iterates over the fields until there are no more fields having that DateStr.
When a package requires sequential access, the package does not support random access of the data at all. There are two modes for sequential access. The first is strict. Fields and metadata must be read in exactly the order they were written. A call to an API subroutine will skip ahead through the data until the operation can be satisfied or until the end of the dataset is reached. Any skipped data is thus inaccessible without a close and reopen. Strict sequential access implies that sequential access is required and that random access is not supported.
The second mode is framed. The access to the data is sequential over DateStr sets of fields but random within a set. The outer loop in the example above represents framed sequential access. Note that the allowed form of random access always implies framed sequential access.
One important reason for allowing sequential access (either framed or strict) in the API specification is to provide a way for implementations to perform buffering to or from datasets or coupled models. On writing, all fields in the same DateStr set can be cached as a frame within a package and then written out or sent to a peer model after the writing application has finished writing all the fields of the frame, as indicated by the ext_pkg_end_of_frame call. On reading, the package can read ahead or receive an entire new frame when the ext_pkg_get_next_time or ext_pkg_set_time routines are called.
Model coupling through the WRF I/O API¶
In addition to explicit reading and writing of files, the WRF I/O API provides support for coupling of model components. In the context of I/O, the open subroutine calls may open a file for reading or writing. In the coupling case they open data streams through which model boundary conditions can be exchanged. The read and write routines receive and send boundary data to and from components. In the process, the necessary re-gridding operations are performed within the coupling mechanism that implements the interface. Coupling interfaces may support exchange of only 2-D fields or full 3-D fields (although performance may suffer). This and other behavior of the coupling implementation are available through the ext_pkg_inquiry routine.
Model coupling implementations of the WRF I/O API may be parallel (and thus collective; the MCT implementation is an example) or single-processor (MCEL is an example).
Coupling implementations of the API can also make use of the begin/commit functionality, which can be used to implement coupling by frames. During the training phase, the read/write calls provide the API with a list of variables that are to be exchanged between components during each frame. Once the commit call has been made the set of fields that make up a frame has been defined and the API can use that information to aggregate communication or otherwise improve efficiency. On writing, the frame is not considered completed and sent until the write_field for the last field in the frame or get_next_time has been called. On reading, the read_field call for the first field in the frame or get_next_time initiates a new frame, and the frame is considered active until read_field has been called for the last field in the frame or get_next_time has been called for the stream.
Multi-threading¶
The WRF I/O and Model Coupling API is not thread safe and must not be called by more than one concurrently executing thread.
Parallelism¶
An implementation of the WRF I/O and Model Coupling API may support parallel I/O, in which case, calls to I/O API routines are required to be collective that is, if an API routine is called, it must be called by every process on the communicator. An implementation is allowed to specify that it is not parallel and can only be called on a single processor (this assumes that the application collects the data onto a single processor before calling the I/O API). The implementations behavior must be specified in its documentation, and it must indicate whether it is parallel or not in response to an application query using the ext_pkg_inquiry routine.
Arguments to WRF I/O API routines¶
This section describes subroutine arguments common to various routines in the I/O API.
Data Handles
These are descriptors of datasets or data streams. Created by the open routines, they are subsequently passed to the read and write field routines.
System Dependent Information
Many of the API routines accept a string-valued argument that allows an application to pass additional control information to the I/O interface. The format of the string is a comma-separated list of key=value pairs. Combined with the WRF I/O systems ability to open different packages for distinct data streams, this feature provides flexibility to customize I/O and coupling for particular implementations. The package implementer may, but is not required, to do anything special with this information.
Data names and time stamps
From the point of view of a package implementing the I/O API, the timestamp string has no meaning or relationship with any other timestamp other than lexicographic: two strings are either the same or they are different; there is no meaning associated with the timestamp string. The interface does not do time comparisons but it is aware of control breaks (change in the sequence of timestamps in the interface). The interface may also store a record of the sequence in which fields were written to a dataset and provide this information in a way that allows sequential traversal through the dataset but datasets are fundamentally random access by variable name and timestamp string. The interface may assume and expect that all the fields in a frame of data have the same date string and that on writing the calls to the interface to write them will have been called in consecutively.
Field Types
The subroutines accept integer data types as specified below. These data types are defined in the wrf_io_flags.h file that comes with each reference implementation. This file must be included by the application.
WRF_REAL : Single precision real number
WRF_DOUBLE : Double precision real number
WRF_INTEGER : Integer number
WRF_COMPLEX : Single precision complex number
WRF_DOUBLE_COMPLEX : Double precision complex number
WRF_LOGICAL : Logical (boolean)
Communicators
The open subroutines of the interface allow callers to pass up to two communicators with different purposes. For example, one could be a global communicator and the second a communicator for a subset of the processes.
Staggering
Staggered means with respect to mass-point coordinates. For example, in WRF the Eulerian height solver uses an Arakawa C-grid so that the U-velocity is staggered in X, the V-velocity is staggered in Y, and the vertical velocity is staggered in Z. The stagger string is specified to the read_field and write_field using a string consisting of the characters X, Y, and/or Z that specifies which dimensions the field is staggered in (or the empty string if the variable is not staggered in any dimension).
Memory order
Fields have the property of memory order while in model memory; the order in the dataset is package dependent. This information is needed by the write_field and read_field in oder to move data between memory and dataset, possibly transposing the data in the process. The memory order string specifies the order of the dimensions (minor to major from left to right) of the field as it sits in program memory. The direction of the dimension depends on whether X, Y, or Z is capitalized. Uppercase means west to east in X, south to north in Y, and bottom to top in Z with ascending indices. The number of dimensions is implied from the string as well.
XYZ |
Z |
C |
XSZ (west) |
XS (west) |
XZY |
XEZ (east) |
XE (east) |
||
ZXY |
0-D (Scalars) |
YSZ (south) |
YS (south) |
|
XY |
0 (zero) |
YEZ (north) |
YE (north) |
|
YX |
Dimension names
These are the names of the dimensions of the grid upon which lies the variable being read or written (for example latitude).
Domain Start/End
These are the global starting and ending indices for each variable dimension.
Patch Start/End
These are the process-local starting and ending indices (excluding halo points) for each variable dimension.
Memory Start/End
These are the process-local starting and ending indices (including halo points) for each variable dimension.
Status codes
All routines return an integer status argument, which is zero for success. Non-zero integer constant status codes are listed below and are defined by the package in an include file named wrf_status_codes.h and made available by the package build mechanism. Status codes pertaining to coupler implementations of the I/O will be listed in a future release of this document.
WRF_NO_ERR (equivalent to zero) No error
WRF_WARN_NOOP Package implements this routine as NOOP
WRF_WARN_FILE_NF File not found (or incomplete)
WRF_WARN_MD_NF Metadata not found
WRF_WRN_TIME_NF Timestamp not found
WRF_WARN_TIME_EOF No more time stamps
WRF_WARN_VAR_NF Variable not found
WRF_WARN_VAR_END No more variables for the current time
WRF_WARN_TOO_MANY_FILES Too many open files
WRF_WARN_TYPE_MISMATCH Data type mismatch
WRF_WARN_WRITE_RONLY_FILE Attempt to write read only file
WRF_WARN_READ_WONLY_FILE Attempt to read write only file
WRF_WARN_FILE_NOT_OPENED Attempt to access unopened file
WRF_WARN_2DRYRUNS_1VARIABLE Attempt to do 2 trainings for 1 variable
WRF_WARN_READ_PAST_EOF Attempt to read past EOF
WRF_WARN_BAD_DATA_HANDLE Bad data handle
WRF_WARN_WRTLEN_NE_DRRUNLEN Write length not equal training length
WRF_WARN_TOO_MANY_DIMS More dimensions requested than training
WRF_WARN_COUNT_TOO_LONG Attempt to read more data than exists
WRF_WARN_DIMENSION_ERROR Input dimensions inconsistemt
WRF_WARN_BAD_MEMORYORDER Input MemoryOrder not recognized
WRF_WARN_DIMNAME_REDEFINED A dimension name with 2 different lengths
WRF_WARN_CHARSTR_GT_LENDATA String longer than provided storage
WRF_WARN_PACKAGE_SPECIFIC The warning code is specific to package
Fatal Errors:
WRF_ERR_FATAL_ALLOCATION_ERROR Allocation error
WRF_ERR_FATAL_DEALLOCATION_ERR Deallocation error
WRF_ERR_FATAL_BAD_FILE_STATUS Bad file status
WRF_ERR_PACKAGE_SPECIFIC The error code is specific to package
WRF I/O and Model Coupling API Subroutines¶
This section comprises the calling semantics and functional descriptions of the subroutines in the WRF I/O and Model Coupling API.
ext_pkg_ioinit¶
SUBROUTINE ext_pkg_ioinit( SysDepInfo, Status )
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER, INTENT(INOUT) :: Status
Synopsis:
Initialize the WRF I/O system.
Arguments:
SysDepInfo: System dependent information
ext_pkg_ioexit¶
SUBROUTINE ext_pkg_ioexit( Status )
INTEGER, INTENT(INOUT) :: Status
Synopsis:
Shut down the WRF I/O system.
ext_pkg_inquiry¶
SUBROUTINE ext_pkg_inquiry ( Inquiry, Result, Status )
CHARACTER *(*), INTENT(IN) :: Inquiry
CHARACTER *(*), INTENT(OUT) :: Result
INTEGER , INTENT(OUT) :: Status
Synopsis:
Return information about the implementation of the WRF I/O API.
Arguments:
Inquiry: The attribute of the package being queried.
Result: The result of the query.
Description:
This routine provides a way for an application to determine any package specific behaviors or limitations of an implementation of the WRF I/O API. All implementations of the API are required to support the following list of inquiries and responses. In addition, packages may specify additional string valued inquiries and responses provided these are documented.
RANDOM_WRITE REQUIRE or ALLOW or NO
RANDOM_READ REQUIRE or ALLOW or NO
SEQUENTIAL_WRITE STRICT or FRAMED or ALLOW or NO
SEQUENTIAL_READ STRICT or FRAMED or ALLOW or NO
OPEN_READ REQUIRE or ALLOW or NO
OPEN_WRITE REQUIRE or ALLOW or NO
OPEN_COMMIT_READ REQUIRE or ALLOW or NO
OPEN_COMMIT_WRITE REQUIRE or ALLOW or NO
MEDIUM FILE or COUPLED or UNKNOWN
PARALLEL_IO YES or NO
SELF_DESCRIBING YES or NO
SUPPORT_METADATA YES or NO
SUPPORT_3D_FIELDS YES or NO
ext_pkg_open_for_read¶
SUBROUTINE ext_pkg_open_for_read ( DatasetName , Comm1 , Comm2, &
SysDepInfo , DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: DatasetName
INTEGER , INTENT(IN) :: Comm1 , Comm2
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Opens a WRF dataset for reading using the I/O package pkg.
Arguments:
DatasetName: The name of the dataset to be opened.
Comm1: First communicator.
Comm2: Second communicator.
SysDepInfo: System dependent information.
DataHandle: Returned to the calling program to serve as a handle to the
open dataset for subsequent I/O API operations.
Description:
This routine opens a file for reading or a coupler data stream for receiving messages. There is no training phase for this version of the open statement.
ext_pkg_open_for_read_begin¶
SUBROUTINE ext_pkg_open_for_read_begin ( DatasetName , Comm1 , Comm2, &
SysDepInfo , DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: DatasetName
INTEGER , INTENT(IN) :: Comm1 , Comm2
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Begin training phase for the WRF dataset DatasetName using the I/O package Pkg
Arguments:
DatasetName: The name of the dataset to be opened.
Comm1: First communicator.
Comm2: Second communicator.
SysDepInfo: System dependent information.
DataHandle: Returned to the calling program to serve as a handle to the
open dataset for subsequent I/O API operations.
Description:
This routine opens a file for reading or a coupler data stream for receiving messages. The call to this routine marks the beginning of the training phase described in the introduction of this section. The call to ext_pkg_open_for_read_begin must be paired with a call to ext_pkg_open_for_read_commit.
ext_pkg_open_for_read_commit¶
SUBROUTINE ext_pkg_open_for_read_commit( DataHandle , Status )
INTEGER , INTENT(IN ) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
End training phase.
Arguments:
DataHandle: Descriptor for an open dataset.
Description:
This routine switches an internal flag to enable input. The call to ext_pkg_open_for_read_commit must be paired with a call to ext_pkg_open_for_read_begin.
ext_pkg_open_for_write¶
SUBROUTINE ext_pkg_open_for_write ( DatasetName , Comm1 , Comm2, &
SysDepInfo , DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: DatasetName
INTEGER , INTENT(IN) :: Comm1 , Comm2
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Opens a WRF dataset for writing using the I/O package pkg.
Arguments:
DatasetName: The name of the dataset to be opened.
Comm1: First communicator.
Comm2: Second communicator.
SysDepInfo: System dependent information.
DataHandle: Returned to the calling program to serve as a handle to the
open dataset for subsequent I/O API operations.
Description:
This routine opens a file for writing or a coupler data stream for sending messages. There is no training phase for this version of the open statement.
ext_pkg_open_for_write_begin¶
SUBROUTINE ext_pkg_open_for_write_begin( DatasetName , Comm1, Comm2, &
SysDepInfo, DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: DatasetName
INTEGER , INTENT(IN) :: Comm1, Comm2
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Begin data definition phase for the WRF dataset DatasetName using the I/O package Pkg.
Arguments:
DatasetName: The name of the dataset to be opened.
Comm1: First communicator.
Comm2: Second communicator.
SysDepInfo: System dependent information.
DataHandle: Returned to the calling program to serve as a handle to the
open dataset for subsequent I/O API operations.
Description:
This routine opens a file for writing or a coupler data stream for sending messages. The call to this routine marks the beginning of the training phase described in the introduction of this section. The call to ext_pkg_open_for_write_begin must be matched with a call to ext_pkg_open_for_write_commit.
ext_pkg_open_for_write_commit¶
SUBROUTINE ext_pkg_open_for_write_commit( DataHandle , Status )
INTEGER , INTENT(IN ) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
End training phase.
Arguments:
DataHandle: Descriptor for an open dataset.
Description:
This routine switches an internal flag to enable output. The call to ext_pkg_open_for_write_commit must be paired with a call to ext_pkg_open_for_write_begin .
ext_pkg_inquire_opened¶
SUBROUTINE ext_pkg_inquire_opened( DataHandle, DatasetName , DatasetStatus, &
Status )
INTEGER ,INTENT(IN) :: DataHandle
INTEGER ,INTENT(IN) :: DatasetName
CHARACTER*(*) ,INTENT(OUT) :: DatasetStatus
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Inquire if the dataset referenced by DataHandle is open.
Arguments:
DataHandle: Descriptor for an open dataset.
DatasetName: The name of the dataset.
DatasetStatus: Returned status of the dataset. Zero = success. Non-zero status codes are listed below and are in the module wrf_data and made available by the package build mechanism in the inc directory.
WRF_FILE_NOT_OPENED
WRF_FILE_OPENED_NOT_COMMITTED
WRF_FILE_OPENED_AND_COMMITTED
WRF_FILE_OPENED_FOR_READ
Description:
This routine returns one of the four dataset status codes shown above. The status codes WRF_FILE_OPENED_NOT_COMMITTED and WRF_FILE_OPENED_AND_COMMITTED refer to opening for write.
ext_pkg_open_for_update¶
SUBROUTINE ext_pkg_open_for_read ( DatasetName , Comm1 , Comm2, &
SysDepInfo , DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: DatasetName
INTEGER , INTENT(IN) :: Comm1 , Comm2
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Opens a WRF dataset for reading and writing using the I/O package pkg.
Arguments:
DatasetName: The name of the dataset to be opened.
Comm1: First communicator.
Comm2: Second communicator.
SysDepInfo: System dependent information.
DataHandle: Returned to the calling program to serve as a handle to the open dataset for subsequent I/O API operations.
Description:
This routine opens a dataset for reading and writing, and is intended for updating individual fields in-place. There is no training phase for this version of the open statement. This routine has the same calling arguments of ext_ncd_open_for_read but allows both ext_ncd_read_field and ext_ncd_write_field calls on the file handle. It is incumbent upon the application to ensure that ext_ncd_write_field is called only for fields that already exist in the file and that the dimension, order, etc. arguments correspond to the field as it exists in the file. It’s necessary for the application to close the file (using ext_ncd_ioclose) to make sure that the changes get saved to the dataset.
ext_pkg_ioclose¶
SUBROUTINE ext_pkg_ioclose( DataHandle, Status)
INTEGER ,INTENT(IN) :: DataHandle
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Close the dataset referenced by DataHandle.
Arguments:
DataHandle: Descriptor for an open dataset.
ext_pkg_read_field¶
SUBROUTINE ext_pkg_read_field ( DataHandle , DateStr , VarName , &
Field , FieldType , Comm1 , Comm2 &
DomainDesc , MemoryOrder , Stagger , &
DimNames , &
DomainStart , DomainEnd , &
MemoryStart , MemoryEnd , &
PatchStart , PatchEnd , &
Status )
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: DateStr
CHARACTER*(*) ,INTENT(IN) :: VarName
type ,INTENT(IN) :: Field(*)
INTEGER ,INTENT(IN) :: FieldType
INTEGER ,INTENT(IN) :: Comm1
INTEGER ,INTENT(IN) :: Comm2
INTEGER ,INTENT(IN) :: DomainDesc
CHARACTER*(*) ,INTENT(IN) :: MemoryOrder
CHARACTER*(*) ,INTENT(IN) :: Stagger
CHARACTER*(*) , DIMENSION (*) ,INTENT(IN) :: DimNames
INTEGER ,DIMENSION(*) ,INTENT(IN) :: DomainStart, DomainEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: MemoryStart, MemoryEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: PatchStart, PatchEnd
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Read the variable named VarName from the dataset pointed to by DataHandle.
Arguments:
DataHandle: Descriptor for an open dataset.
DateStr: A string providing the timestamp for the variable to be written.
VarName: A string containing the name of the variable to be written.
Field: A pointer to the variable to be written.
FieldType: Field attribute
Comm1: First communicator
Comm2: Second communicator
DomainDesc: Additional argument that may be used to pass a communication package specific domain descriptor.
MemoryOrder: Field attribute
Stagger: Field attribute
DimNames: Field attribute
DomainStart: Field attribute
DomainEnd: Field attribute
MemoryStart: Field attribute
MemoryEnd: Field attribute
PatchStart: Field attribute
PatchEnd: Field attribute
Description:
This routine reads the variable named VarName in location Field from the dataset pointed to by DataHandle at time DateStr. No data are read if this routine is called during training.
ext_pkg_write_field¶
SUBROUTINE ext_pkg_write_field ( DataHandle , DateStr , VarName , &
Field , FieldType , Comm1 , Comm2 &
DomainDesc , MemoryOrder , Stagger , &
DimNames , &
DomainStart , DomainEnd , &
MemoryStart , MemoryEnd , &
PatchStart , PatchEnd , &
Status )
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: DateStr
CHARACTER*(*) ,INTENT(IN) :: VarName
type ,INTENT(IN) :: Field(*)
INTEGER ,INTENT(IN) :: FieldType
INTEGER ,INTENT(IN) :: Comm1
INTEGER ,INTENT(IN) :: Comm2
INTEGER ,INTENT(IN) :: DomainDesc
CHARACTER*(*) ,INTENT(IN) :: MemoryOrder
CHARACTER*(*) ,INTENT(IN) :: Stagger
CHARACTER*(*) , DIMENSION (*) ,INTENT(IN) :: DimNames
INTEGER ,DIMENSION(*) ,INTENT(IN) :: DomainStart, DomainEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: MemoryStart, MemoryEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: PatchStart, PatchEnd
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Write the variable named VarName to the dataset pointed to by DataHandle.
Arguments:
DataHandle: Descriptor for an open dataset.
DateStr: A string providing the timestamp for the variable to be written.
VarName: A string containing the name of the variable to be written.
Field: A pointer to the variable to be written.
FieldType: Field attribute
Comm1: First communicator
Comm2: Second communicator
DomainDesc: Additional argument that may be used to pass a communication package specific domain descriptor.
MemoryOrder: Field attribute
Stagger: Field attribute
DimNames: Field attribute
DomainStart: Field attribute
DomainEnd: Field attribute
MemoryStart: Field attribute
MemoryEnd: Field attribute
PatchStart: Field attribute
PatchEnd: Field attribute
Description:
This routine writes the variable named VarName in location Field to the dataset pointed to by DataHandle at time DateStr. No data are written if this routine is called during training.
ext_pkg_get_next_var¶
SUBROUTINE ext_pkg_get_next_var(DataHandle, VarName, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(OUT) :: VarName
INTEGER ,INTENT(OUT) :: Status
Synopsis:
On reading, this routine returns the name of the next variable in the current time frame.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
VarName: A string returning the name of the next variable.
Description:
This routine applies only to a dataset that is open for read in a package that supports sequential framed access. Otherwise, the package sets Status to WRF_WARN_NOOP and returns with no effect. For the active DateStr (set by ext_pkg_set_time or ext_pkg_get_next_time) the name of the next unaccessed variable in the frame is returned in VarName. The variable name returned in VarName may then be used as the VarName argument to ext_pkg_read_field. If there are no more variables in the set the the currently active DateStr, a non-zero Status, WRF_WARN_VAR_END, is returned.
ext_pkg_end_of_frame¶
SUBROUTINE ext_pkg_end_of_frame(DataHandle, Status)
INTEGER ,INTENT(IN) :: DataHandle
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Write an end-of-frame marker onto the dataset.
Arguments:
DataHandle: Descriptor for a dataset that is open.
Description:
This applies only to datasets opened for write and for implementations that support sequential framed access. Otherwise the routine sets Status to WRF_WARN_NOOP and returns without an effect.
The WRF I/O API is optimized (but not required) to write all the output variables in order at each output time step. All the output variables at a time step are called a frame. After a frame is read or written, ext_pkg_end_of_frame must be called which can (but is not required to) write an end-of-file mark. The end-of-file marks allow for buffering of the output.
Recommended use: It is recommended that applications use ext_pkg_end_of_frame when writing data as sets of fields with the same DateStr, even if the particular package does not support it except as a NOOP. Writing application output code this way will make the code easily adaptable to implementations of the WRF I/O API that allow or require an end-of-frame marker.
ext_pkg_iosync¶
SUBROUTINE ext_pkg_iosync(DataHandle, Status)
INTEGER ,INTENT(IN) :: DataHandle
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Synchronize the disk copy of a dataset with memory buffers.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Description:
Synchronizes any I/O implementation buffers with respect to dataset.
ext_pkg_inquire_filename¶
SUBROUTINE ext_pkg_inquire_filename(DataHandle, Filename, FileStatus, Status)
INTEGER ,INTENT(IN) :: DataHandle
INTEGER ,INTENT(OUT) :: Filename
INTEGER ,INTENT(OUT) :: FileStatus
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Returns the Filename and FileStatus associated with DataHandle.
Arguments:
DataHandle: Descriptor for a dataset that is open.
Filename: The file name associated with DataHandle
FileStatus: The status of the file associated with DataHandle.
ext_pkg_get_var_info¶
SUBROUTINE ext_pkg_get_var_info(DataHandle, VarName, Ndim, MemoryOrder, DomainStart, DomainEnd, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: VarName
INTEGER ,INTENT(OUT) :: NDim
CHARACTER*(*) ,INTENT(OUT) :: MemoryOrder
INTEGER ,DIMENSION(*) ,INTENT(OUT) :: DomainStart, DomainEnd
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Get information about a variable.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
VarName: A string containing the name of the variable to be read.
Ndim: The number of dimensions of the field data.
MemoryOrder: Field attribute
DomainStart: Field attribute
DomainEnd: Field attribute
Description:
This routine applies only to a dataset that is open for read. This routine returns the number of dimensions, the memory order, and the start and stop indices of the data.
ext_pkg_set_time¶
SUBROUTINE ext_pkg_set_time(DataHandle, DateStr, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: DateStr
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Sets the time stamp.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
DateStr: The time stamp; a 23 character date string of the form 0000-01-01_00:00:00.0000.
Description:
This routine applies only to a dataset that is open for read and if the implementation supports sequential framed access. Otherwise the routine sets WRF_WARN_NOOP and returns with no effect. This routine sets the current frame of fields having the same date string to the value of the argument DateStr.
ext_pkg_get_next_time¶
SUBROUTINE ext_pkg_get_next_time(DataHandle, DateStr, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(OUT) :: DateStr
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Returns the next time stamp.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
DateStr: Returned time stamp; a 23 character date string of the form 0000-01-01_00:00:00.0000.
Description:
This routine applies only to a dataset that is open for read. This routine returns the next time stamp in DateStr. The time stamp character string is the index into the series of values of the variable/array in the dataset. In WRF, this is a 23 character date string of the form 0000-01-01_00:00:00.0000 and is treated as a temporal index.
ext_pkg_get_var_ti_type set of routines¶
This family of functions gets a time independent attribute of a variable of attribute type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_get_var_ti_char (DataHandle, Element, Var, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_get_var_ti_type (DataHandle, Element, Var, Data, Count, OutCount, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
CHARACTER*(*) ,INTENT(IN) :: Var
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUY) :: OutCount
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Read attribute Element of the variable Var from the dataset and store in the array Data.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
Var Name of the variable to which the attribute applies
Data: Array in which to return the data.
Count: The number of words requested.
OutCount: The number of words returned.
Description:
These routines apply only to a dataset that is open for read. They attempt to read Count words of the time independent attribute Element of the variable Var from the dataset and store in the array Data. OutCount is the number of words returned. If the number of words available is greater than or equal to Count then OutCount is equal to Count, otherwise Outcount is the number of words available.
ext_pkg_put_var_ti_type set of routines¶
This family of functions writes a time independent attribute of a variable of attribute type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_put_var_ti_char (DataHandle, Element, Var, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_put_var_ti_type (DataHandle, Element, Var, Data, Count, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
CHARACTER*(*) ,INTENT(IN) :: Var
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Write attribute Element of variable Var from array Data to the dataset.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
Var Name of the variable to which the attribute applies
Data: Array holding the data to be written.
Count: The number of words to be written.
Description:
These routines apply only to a dataset that is opened and committed. They write Count words of the time independent attribute Element of the variable Var stored in the array Data to the dataset pointed to by DataHandle.
ext_pkg_get_var_td_type set of routines¶
This family of functions gets a variable attribute at a specified time where the attribute is of type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_get_var_td_char (DataHandle, Element, DateStr, Var, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_get_var_td_type (DataHandle, Element, DateStr, Var, Data, Count, OutCount, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
CHARACTER*(DateStrLen),INTENT(IN) :: DateStr
CHARACTER*(*) ,INTENT(IN) :: Var
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUY) :: OutCount
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Read attribute Element of the variable Var at time DateStr from the dataset and store in the array Data.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
DateStr Time stamp; a 23 character date string of the form 0000-01-01_00:00:00.0000
Var Name of the variable to which the attribute applies
Data: Array in which to return the data.
Count: The number of words requested.
OutCount: The number of words returned.
Description:
These routines apply only to a dataset that is open for read. They attempt to read Count words of the attribute Element of the variable Var at time DateStr from the dataset and store in the array Data. OutCount is the number of words returned. If the number of words available is greater than or equal to Count then OutCount is equal to Count, otherwise Outcount is the number of words available.
ext_pkg_put_var_td_type set of routines¶
This family of functions writes a variable attribute at a specified time where the attribute is of type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_put_var_td_char (DataHandle, Element, DateStr, Var, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_put_var_td_type (DataHandle, Element, DateStr, Var, Data, Count, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
CHARACTER*(DateStrLen),INTENT(IN) :: DateStr
CHARACTER*(*) ,INTENT(IN) :: Var
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Write attribute Element of the variable Var at time DateStr from the array Data to the dataset.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
DateStr Time stamp; a 23 character date string of the form 0000-01-01_00:00:00.0000
Var Name of the variable to which the attribute applies
Data: Array in which to return the data.
Count: The number of words requested.
Description:
These routines apply only to a dataset that is either open and not committed or open and committed. If the dataset is opened and not committed then the storage area on the dataset is set up but no data is written to the dataset. If the dataset is open and committed then data is written to the dataset. These routines write Count words of the attribute Element of the variable Var at time DateStr from the array Data to the dataset.
ext_pkg_get_dom_ti_type set of routines¶
This family of functions gets time independent domain metadata of type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_get_dom_ti_char (DataHandle, Element, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_get_dom_ti_type (DataHandle, Element, Data, Count, OutCount, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUY) :: OutCount
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Reads time independent domain metadata named Element from the dataset into the array Data.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
Data: Array in which to return the data.
Count: The number of words requested.
OutCount: The number of words returned.
Description:
These routines apply only to a dataset that is open for read. They attempt to read Count words of time independent domain metadata named Element into the array Data from the dataset pointed to by DataHandle. OutCount is the number of words returned. If the number of words available is greater than or equal to Count then OutCount is equal to Count, otherwise Outcount is the number of words available.
ext_pkg_put_dom_ti_type set of routines¶
This family of functions writes time independent domain metadata of type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_put_dom_ti_char (DataHandle, Element, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_put_dom_ti_type (DataHandle, Element, Data, Count, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Write time independent domain attribute Element from the array Data to the dataset.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
Data: Array holding the data.
Count: The number of words to write.
Description:
These routines apply only to a dataset that is open and committed. They write Count words of time independent domain metadata named Element from the array Data to the dataset pointed to by DataHandle.
ext_pkg_get_dom_td_type set of routines¶
This family of functions gets time dependent domain metadata of type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_get_dom_td_char (DataHandle, Element, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_get_dom_td_type (DataHandle, Element, Data, Count, OutCount, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
CHARACTER*(*) ,INTENT(IN) :: DateStr
type ,INTENT(OUT) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUY) :: OutCount
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Reads domain metadata named Element at time DateStr from the dataset into the array Data.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
DateStr: Time stamp; a 23 character date string of the form 0000-01-01_00:00:00.0000
Data: Array in which to return the data.
Count: The number of words requested.
OutCount: The number of words returned.
Description:
These routines apply only to a dataset that is open for read. They attempt to read Count words of domain metadata named Element, at time DateStr, into the array Data from the dataset pointed to by DataHandle. OutCount is the number of words returned. If the number of words available is greater than or equal to Count then OutCount is equal to Count, otherwise Outcount is the number of words available.
ext_pkg_put_dom_td_type set of routines¶
This family of functions puts time dependent domain metadata of type type where type can be:
real
double
integer
logical
character
If type is character, then the function has the form:
SUBROUTINE ext_pkg_get_dom_td_char (DataHandle, Element, Data, Status)
Otherwise it has the form:
SUBROUTINE ext_pkg_get_dom_td_type (DataHandle, Element, Data, Count, OutCount, Status)
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: Element
CHARACTER*(*) ,INTENT(IN) :: DateStr
type ,INTENT(IN) :: Data(*)
INTEGER ,INTENT(IN) :: Count
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Writes domain metadata named Element at time DateStr from the dataset into the array Data.
Arguments:
DataHandle: Descriptor for a dataset that is open for read.
Element: The name of the data.
DateStr: Time stamp; a 23 character date string of the form 0000-01-01_00:00:00.0000
Data: Array holding the data.
Count: The number of words requested.
OutCount: The number of words returned.
Description:
These routines apply only to a dataset that is open for write. They attempt to write Count words of domain metadata named Element, at time DateStr, into the array Data from the dataset pointed to by DataHandle.
ext_pkg_warning_string¶
SUBROUTINE ext_pkg_warning_str ( Code, ReturnString, Status)
INTEGER ,INTENT(IN) :: Code
CHARACTER*(*) ,INTENT(OUT) :: ReturnString
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Given an status value returned by an API routine, set the ReturnString to a descriptive value. The string passed to this routine must be 256 characters or larger.
Arguments:
Code: Integer status from an I/O API call
ReturnString: String containing message describing error
ext_pkg_error_string¶
SUBROUTINE ext_pkg_error_str ( Code, ReturnString, Status)
INTEGER ,INTENT(IN) :: Code
CHARACTER*(*) ,INTENT(OUT) :: ReturnString
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Given an status value returned by an API routine, set the ReturnString to a descriptive value. The string passed to this routine must be 256 characters or larger.
Arguments:
Code: Integer status from an I/O API call
ReturnString: String containing message describing error
APPENDIX B: MCT Reference Implementation¶
Interpolation is implemented using the sparse matrix multiplication capability provided by MCT. Currently, the matrix coefficients are stored in an ASCII file. The user provides the base name of this file to the OPEN routines described below. Since the coefficients vary depending on grid staggering, the full name of the file is constructed by combining the base name with the staggering characters passed to the read/write routines.
The behavior of the implementation depends on whether it is called by model components that are executed sequentially or concurrently. If they are executed concurrently, then every processor initializes this package with its component name since the MCT initialization routine requires this information. If the components execute sequentially then the component names are not unique to each processor. In this case, the package is initialized with list of all components. The API allows for both kinds of initialization within a coupled model. The sequential form overrides the concurrent form. This allows the modeler to change modes relatively easily. The concurrent initialization calls are made from within each model. If sequential coupling is desired, the model leaves in the concurrent calls but adds a sequential call to the coupler driver.
Each time an EXT_MCT_OPEN_FOR_WRITE_BEGIN is called, the user is required to specify the component names of both the sender and receiver since MCT needs this information to set up a data exchange between the two components. Technically, in the concurrent case, only one is required since the name of the sender was obtained when the package was initialized. However, for symmetry, the package will always require both. The same logic applies to EXT_MCT_OPEN_FOR_READ_BEGIN. In the API routines, some of the arguments passed in are unused as will be discussed below.
blank section¶
ext_mct_ioinit¶
SUBROUTINE ext_mct_ioinit( SysDepInfo, Status )
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER, INTENT(INOUT) :: Status
Synopsis:
Initialize the Mct coupler implementation of the WRF I/O API.
Arguments:
SysDepInfo: System dependent information
If coupling is being done concurrently, then SysDepInfo must consist of the following key/value pair:
SysDepInfo=component_name=model_comp_name
If coupling is being done sequentially, then SysDepInfo must consist of a list of keys and values for all model components as follows:
SysDepInfo=component1=model1_comp_name, component2=model2_comp_name,
ext_mct_ioexit¶
SUBROUTINE ext_mct_ioexit( Status )
INTEGER, INTENT(INOUT) :: Status
Synopsis:
Shut down the WRF I/O system.
ext_mct_inquiry¶
SUBROUTINE ext_mct_inquiry ( Inquiry, Result, Status )
CHARACTER *(*), INTENT(IN) :: Inquiry
CHARACTER *(*), INTENT(OUT) :: Result
INTEGER , INTENT(OUT) :: Status
Synopsis:
Return information about the Mct implementation of the WRF I/O API.
Arguments:
Inquiry: The attribute of the package being queried.
Result: The result of the query.
Description:
Below are the Mct implementation specific valid queries and results.
RANDOM_WRITE NO
RANDOM_READ NO
SEQUENTIAL_WRITE FRAMED
SEQUENTIAL_READ FRAMED
OPEN_READ NO
OPEN_WRITE NO
OPEN_COMMIT_READ REQUIRED
OPEN_COMMIT_WRITE REQUIRED
MEDIUM COUPLED
PARALLEL_IO YES
SELF_DESCRIBING NO
SUPPORT_METADATA NO
SUPPORT_3D_FIELDS NO
EXECUTION_MODE CONCURRENT or SEQUENTIAL
ext_mct_open_for_read_begin¶
SUBROUTINE ext_mct_open_for_read_begin ( ComponentName , GlobalComm , CompComm, &
SysDepInfo , DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: ComponentName
INTEGER , INTENT(IN) :: GlobalComm , CompComm
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Begin training phase for the WRF dataset DatasetName using the I/O package Mct
Arguments:
ComponentName The name of the model component from which data will be read.
GlobalComm: Communicator for all processors.
CompComm: Communicator for processors specific to the calling component.
SysDepInfo: System dependent information described below.
DataHandle: Returned to the calling program to serve as a handle to the open coupler stream for subsequent I/O API operations.
Description:
This routine opens a coupler data stream for receiving messages. The call to this routine marks the beginning of the training phase described in the introduction of this section. The call to ext_mct_open_for_read_begin must be paired with a call to ext_mct_open_for_read_commit. SysDepInfo must contain two key/value pairs as follows:
SysDepInfo=sparse_matrix_base_name=base_filename, component_name=comp_name
As described earlier, base_filename is the base name of the file containing the sparse matrix coefficients. comp_name is the name of the component originating the read operation. In the concurrent case, the communicator CompComm is associated with this component. In the sequential case, both GlobalComm and CompComm must be the global communicator.
ext_mct_open_for_read_commit¶
SUBROUTINE ext_mct_open_for_read_commit( DataHandle , Status )
INTEGER , INTENT(IN ) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
End training phase.
Arguments:
DataHandle: Descriptor for an open coupler stream.
Description:
This routine indicates to the Mct implementation that the training phase is over and all subsequent read operations should actually receive data from the other component.
ext_mct_open_for_write_begin¶
SUBROUTINE ext_mct_open_for_write_begin ( ComponentName , GlobalComm , CompComm, &
SysDepInfo , DataHandle , Status )
CHARACTER *(*), INTENT(IN) :: ComponentName
INTEGER , INTENT(IN) :: GlobalComm , CompComm
CHARACTER *(*), INTENT(IN) :: SysDepInfo
INTEGER , INTENT(OUT) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
Begin training phase for the WRF dataset DatasetName using the I/O package Mct
Arguments:
ComponentName The name of the model component to which data will be written.
GlobalComm: Communicator for all processors.
CompComm: Communicator for processors specific to the calling component.
SysDepInfo: System dependent information described below.
DataHandle: Returned to the calling program to serve as a handle to the open coupler stream for subsequent I/O API operations.
Description:
This routine opens a coupler data stream for sending messages. The call to this routine marks the beginning of the training phase described in the introduction of this section. The call to ext_mct_open_for_write_begin must be paired with a call to ext_mct_open_for_write_commit. SysDepInfo must contain two key/value pairs as follows:
SysDepInfo=sparse_matrix_base_name=base_filename, component_name=comp_name
As described earlier, base_filename is the base name of the file containing the sparse matrix coefficients. comp_name is the name of the component originating the write operation. In the concurrent case, the communicator CompComm is associated with this component. In the sequential case, both GlobalComm and CompComm must be the global communicator.
ext_mct_open_for_write_commit¶
SUBROUTINE ext_mct_open_for_write_commit( DataHandle , Status )
INTEGER , INTENT(IN ) :: DataHandle
INTEGER , INTENT(OUT) :: Status
Synopsis:
End training phase.
Arguments:
DataHandle: Descriptor for an open coupler stream.
Description:
This routine indicates to the Mct implementation that the training phase is over and all subsequent write operations should actually send data to the other component.
ext_mct_read_field¶
SUBROUTINE ext_mct_read_field ( DataHandle , DateStr , VarName , &
Field , FieldType , GlobalComm , &
CompComm, &
DomainDesc , MemoryOrder , Stagger , &
DimNames , &
DomainStart , DomainEnd , &
MemoryStart , MemoryEnd , &
PatchStart , PatchEnd , &
Status )
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: DateStr
CHARACTER*(*) ,INTENT(IN) :: VarName
type ,INTENT(IN) :: Field(*)
INTEGER ,INTENT(IN) :: FieldType
INTEGER ,INTENT(IN) :: GlobalComm
INTEGER ,INTENT(IN) :: CompComm
INTEGER ,INTENT(IN) :: DomainDesc
CHARACTER*(*) ,INTENT(IN) :: MemoryOrder
CHARACTER*(*) ,INTENT(IN) :: Stagger
CHARACTER*(*) , DIMENSION (*) ,INTENT(IN) :: DimNames
INTEGER ,DIMENSION(*) ,INTENT(IN) :: DomainStart, DomainEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: MemoryStart, MemoryEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: PatchStart, PatchEnd
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Receive the variable named VarName from the component pointed to by DataHandle.
Arguments:
DataHandle: Descriptor for an open coupler stream.
DateStr: Not Used
VarName: A string containing the name of the variable to be received.
Field: A pointer to the variable to be received.
FieldType: Data type of the variable.
GlobalComm: Communicator for all processors.
CompComm: Communicator for processors specific to the calling component.
DomainDesc: Not Used.
MemoryOrder: Not Used
Stagger: Staggering of the variable on the grid.
DimNames: Not Used
DomainStart: Field attribute (see Section 1.8 )
DomainEnd: Field attribute
MemoryStart: Field attribute
MemoryEnd: Field attribute
PatchStart: Field attribute
PatchEnd: Field attribute
Description:
This routine receives the variable named VarName in location Field from the component pointed to by DataHandle. No data are received if this routine is called during training. Currently, only fields of type WRF_REAL are supported. The Stagger argument is combined with the sparse matrix base name specified in the Open call to form a complete sparse matrix file name.
ext_mct_write_field¶
SUBROUTINE ext_mct_write_field ( DataHandle , DateStr , VarName , &
Field , FieldType , GlobalComm , &
CompComm, &
DomainDesc , MemoryOrder , Stagger , &
DimNames , &
DomainStart , DomainEnd , &
MemoryStart , MemoryEnd , &
PatchStart , PatchEnd , &
Status )
INTEGER ,INTENT(IN) :: DataHandle
CHARACTER*(*) ,INTENT(IN) :: DateStr
CHARACTER*(*) ,INTENT(IN) :: VarName
type ,INTENT(IN) :: Field(*)
INTEGER ,INTENT(IN) :: FieldType
INTEGER ,INTENT(IN) :: GlobalComm
INTEGER ,INTENT(IN) :: CompComm
INTEGER ,INTENT(IN) :: DomainDesc
CHARACTER*(*) ,INTENT(IN) :: MemoryOrder
CHARACTER*(*) ,INTENT(IN) :: Stagger
CHARACTER*(*) , DIMENSION (*) ,INTENT(IN) :: DimNames
INTEGER ,DIMENSION(*) ,INTENT(IN) :: DomainStart, DomainEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: MemoryStart, MemoryEnd
INTEGER ,DIMENSION(*) ,INTENT(IN) :: PatchStart, PatchEnd
INTEGER ,INTENT(OUT) :: Status
Synopsis:
Send the variable named VarName to the component pointed to by DataHandle.
Arguments:
DataHandle: Descriptor for an open coupler stream.
DateStr: Not Used
VarName: A string containing the name of the variable to be sent.
Field: A pointer to the variable to be sent.
FieldType: Data type of the variable.
GlobalComm: Communicator for all processors.
CompComm: Communicator for processors specific to the calling component.
DomainDesc: Not Used.
MemoryOrder: Not Used
Stagger: Staggering of the variable on the grid.
DimNames: Not Used
DomainStart: Field attribute
DomainEnd: Field attribute
MemoryStart: Field attribute
MemoryEnd: Field attribute
PatchStart: Field attribute
PatchEnd: Field attribute
Description:
This routine sends the variable named VarName in location Field to the component pointed to by DataHandle. No data are set if this routine is called during training. Currently, only fields of type WRF_REAL are supported. The Stagger argument is combined with the sparse matrix base name specified in the Open call to form a complete sparse matrix file name.